notebook高级技巧
网上有很多jupyter的使用技巧。但我相信,这篇文章会让你全面涨姿势。很多用法,你应该没见过。
1. 环境变量
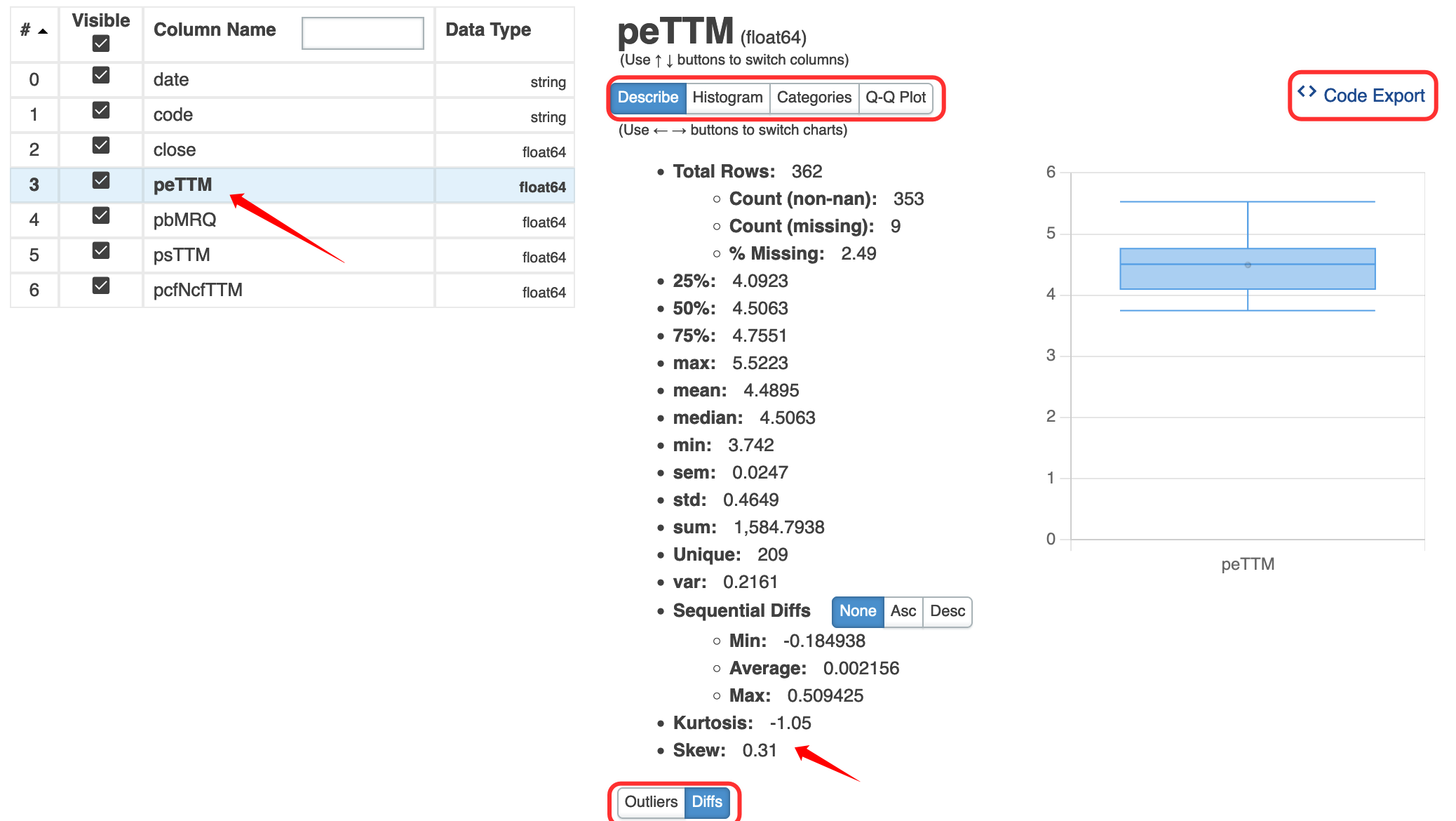
默认情况下,jupyter notebook/lab不会读取你主机的环境变量。如果有一些secret(比如账号、密码)需要通过环境变量传递给notebook的话,我们需要修改它的kernel.json文件。
首先,我们通过 jupyter kernelspec list来获取kernel所在的位置。比如,在我们的课程环境中,我们将得到以下输出:
>>> jupyter kernelspec list
Available kernels:
python3 C:\Users\Administrator\software\anaconda3\envs\lianghua\share\jupyter\kernels\python3
lianghua C:\Users\Administrator\AppData\Roaming\jupyter\kernels\lianghua
我们的课程环境中要使用的kernel,就是lianghua这个名字对应的kernel。下面,我们修改它的配置文件:
用windows vscode修改
C:\Users\Administrator\AppData\Roaming\jupyter\kernels\lianghua\kernel.json
这个文件类似于:
{
"argv": [
"C:\\Users\\Administrator\\software\\anaconda3\\envs\\lianghua\\python.exe",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "lianghua3.12.4",
"language": "python",
"metadata": {
"debugger": true
}
}
我们增加一项,名为"env":
{
"metadata": ...,
"env": {
"TZ": "Asia/Shanghai"
}
}
保存后,在notebook菜单栏中选择shutdown kernel,然后重新打开notebook文件。这样我们就可以在notebook中看到新增的环境变量TZ了:
%env #可以看到'AZ'项为上海
在课程学习中,需要配置你自己的tushare-token,或者jqdatasdk的账号、密码,建议你通过这种方式来配置。
2. 魔法命令
几乎每一个使用过Jupyter Notebook的人,都会注意到它的魔法(magic)功能。具体来说,它是一些适用于整个单元格、或者某一行的魔术指令。
比如,我们常常会好奇,究竟是pandas的刀快,还是numpy的剑更利。在量化中,我们常常需要寻找一组数据的某个分位数。在numpy中,有percentile方法,quantile则是她的pandas堂姊妹。要不,我们就让这俩姐妹比一比身手好了。有一个叫timeit的魔法,就能完成这任务。
不过,我们先得确定她们是否真有可比性。
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
print(np.percentile(array, 95))
series.quantile(0.95)
1.6430590195631314
1.6430590195631314
两次输出的结果都是一样,说明这两个函数确实是有可比性的。
在上面的示例中,要显示两个对象的值,我们只对前一个使用了print函数,后一个则省略掉了。这是notebook的一个功能,它会默认地显示单元格最后输出的对象值。这个功能很不错,要是把这个语法扩展到所有的行就更好了。
不用对神灯许愿,这个功能已经有了!只要进行下面的设置:
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
在一个单独的单元格里,运行上面的代码,之后,我们就可以省掉print:
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
# 这一行会输出一个浮点数
np.percentile(array, 95)
# 这一行也会输出一个浮点数
series.quantile(0.95)
1.6467672500218886
1.6467672500218886
这将显示出两行一样的数值。这是今天的第一个魔法。
现在,我们就来看看,在百万数据中探囊取物,谁的身手更快一点?
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
%timeit np.percentile(array, 95)
%timeit series.quantile(0.95)
4.59 ms ± 10.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.82 ms ± 14.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
我们使用%timeit来测量函数的运行时间。其输出结果是:
之前测试过是反过来的结果
26.7 ms ± 5.67 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
21.6 ms ± 837 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
之前的结论看起来pandas更快啊。而且它的性能表现上更稳定,标准差只有numpy的1/7。mean±std什么的,量化人最熟悉是什么意思了。
新台式电脑又是numpy更快,可能后续再测试对比吧。
这里的timeit,就是jupyter支持的魔法函数之一。又比如,在上面打印出来的分位数,有16位小数之多,真是看不过来啊。能不能只显示3位呢?当然有很多种方法做到这一点,比如,我们可以用f-str语法:
f"{np.percentile(array, 95):.3f}"
'1.648'
啰哩啰嗦的,说好要Pythonic的呢?不如试试这个魔法吧:
%precision 3
np.percentile(array, 95)
'%.3f'
1.648
之后每一次输出浮点数,都只有3位小数了,是不是很赞?
如果我们在使用一个第三方的库,看了文档,(下面的omicron我还没安装好,所以沿用了网上的代码)觉得它还没说明白,想看它的源码,怎么办?可以用psource魔法:
from omicron import tf
%psource tf.int2time
这会显示tf.int2time函数的源代码:
@classmethod
def int2time(cls, tm: int) -> datetime.datetime:
"""将整数表示的时间转换为`datetime`类型表示
examples:
>>> TimeFrame.int2time(202005011500)
datetime.datetime(2020, 5, 1, 15, 0)
Args:
tm: time in YYYYMMDDHHmm format
Returns:
转换后的时间
"""
s = str(tm)
# its 8 times faster than arrow.get()
return datetime.datetime(
int(s[:4]), int(s[4:6]), int(s[6:8]), int(s[8:10]), int(s[10:12])
)
看起来Zillionare-omicron的代码,文档还是写得很不错的。能和numpy一样,在代码中包括示例,并且示例能通过doctest的量化库,应该不多。
Jupyter的魔法很多,记不住怎么办?这里有两个魔法可以用。一是%lsmagic:
%lsmagic
这会显示为:
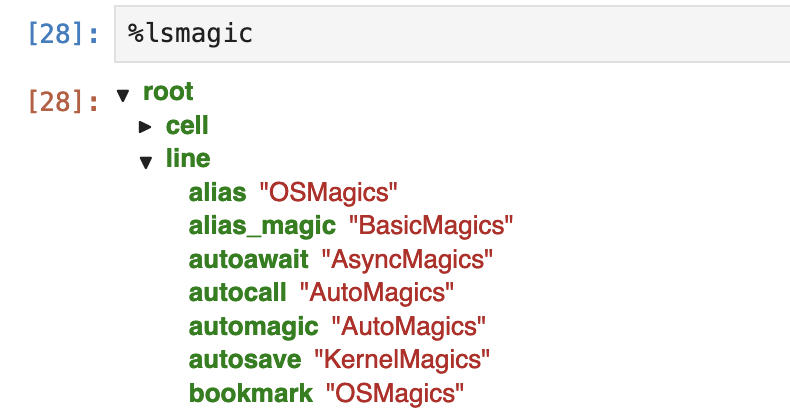
确实太多魔法了!不过,很多命令是操作系统命令的一部分。另一个同样性质的魔法指令是%quickref,它的输出大致如下:
IPython -- An enhanced Interactive Python - Quick Reference Card
================================================================
obj?, obj?? : Get help, or more help for object (also works as
?obj, ??obj).
?foo.*abc* : List names in 'foo' containing 'abc' in them.
%magic : Information about IPython's 'magic' % functions.
Magic functions are prefixed by % or %%, and typically take their arguments
without parentheses, quotes or even commas for convenience. Line magics take a
single % and cell magics are prefixed with two %%.
Example magic function calls:
...
输出内容大约有几百行,一点也不quick!
3. 在vscode中使用jupyter
如果有可能,我们应该尽可能地利用vscode的jupyter notebook。vscode中的jupyter可能在界面元素的安排上弱于浏览器(即原生Jupyter),比如,单元格之间的间距太大,无法有效利用屏幕空间,菜单命令少于原生jupyter等等。但仍然vscode中的jupyter仍然有一些我们难于拒绝的功能。
首先是代码提示。浏览器中的jupyter是BS架构,它的代码提示响应速度比较慢,因此,只有在你按tab键之后,jupyter才会给出提示。在vscode中,代码提示的功能在使用体验上与原生的python开发是完全一样的。
其次,vscode中的jupyter的代码调试功能更好。原生的Jupyter中进行调试可以用%pdb或者%debug这样的magic,但体验上无法与IDE媲美。
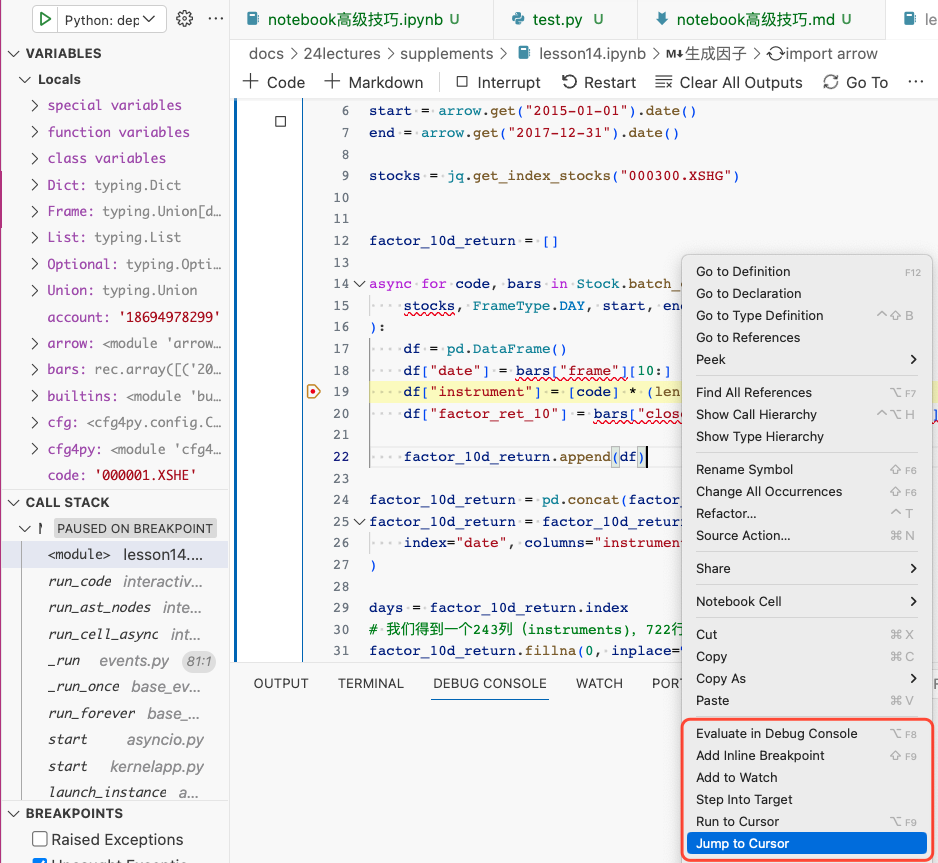
还有一点功能是原生Jupyter无法做到的,就是最后编辑位置导航。如果我们有一个很长的notebook,在第100行调用第10行写的一个函数,发现出错,要转到第10行进行修改,修改完成后,再回到第100行继续编辑,这在原生jupyter中是做不到的。通常我们只能在这些地方,插入markdown cell,然后利用标题来进行快速导航,但仍然无法准确定位到具体的行。但这个功能在IDE里是必备功能。我们在vscode中编辑notebook,这个功能仍然具备。
notebook适于探索。但如果最终我们要将其工程化,我们还必须将其转换成为python文件。vscode提供了非常好的notebook转python文件功能。下面是本文的notebook版本转换成python时的样子:

转换后的notebook中,原先的markdown cell,转换成注释,并且以# %% [markdown]起头;而原生的python cell,则是以# %%起头,这些单元格仍然是可以执行的。由于配置的原因,在我的工作区里,隐藏了这些toolbar,实际上它们看起来像这样:
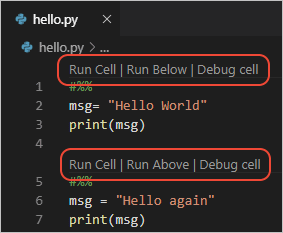
这个特性被称为Python Interactive Window,可以在vscode的文档vscode中查看。
我们从notebook转换成python文件,但它仍然可以像notebook一样,逐单元格执行,这就像是个俄罗斯套娃。
 发表于 2024-9-3 11:51:44
发表于 2024-9-3 11:51:44
 |Archiver|手机版|小黑屋|bioinfoer
( 萌ICP备20244422号 )
|Archiver|手机版|小黑屋|bioinfoer
( 萌ICP备20244422号 )