在量化分析中,投资者使用计算机编写程序,以历史市场数据为基础,通过模型建立和优化来判断市场趋势和进行投资决策。数据(包括行情数据、基本面数据、财务数据等等)是量化分析的基础。
1990 年底,上交所成立时,交易是依靠红马甲喊单撮合的。每个交易日,各家券商交易员挤在一起,手中抓着标着股票代码的小纸条,用力地喊着出价。每当一家券商的交易员大喊“买入”,一群卖方交易员便紧张地挤在一起,争相抛售股票。在这个拥挤的大厅里,每个人都面带紧张的表情,眼睛紧盯着交易屏幕,寻找着最新的交易信息。而每当一只股票价格发生波动,整个交易厅就会一片骚动。有些人会立即举起手中的纸条,向交易员报价,希望能够抓住市场机会。在这个手工竞价交易的时代,每个交易员的工作都非常繁琐,需要手动记录和处理大量的数据和信息。交易员们通常需要长时间地待在交易厅里,时刻准备着应对市场的变化。显然这种落后的交易方式下,是无法提供量化需要的条件的。
A 股的量化史可以追溯到 2005 年 8 月,当时嘉实元和稳健成长证券投资基金成立,主打量化投资策略。在此前后,一些券商、金融机构和软件服务商开始了相关数据的收集与整理。比如成立于 1997 年的万得 (Wind) 财经,它提供的数据涵盖了 A 股市场的股票、基金、债券、衍生品等多个领域,是 A 股市场的重要数据来源之一。随后,又出现了一批象通达信、同花顺、东方财富这样的行情软件开发商,他们也开始提供面向终端的行情数据和基于 API 的数据服务。
目前,机构投资者选择的金融终端主要有东方财富 Choice 以及 Wind 资讯金融终端,数据源(库)供应商主要有 Wind 资讯、恒生聚源、朝阳永续、天软、巨潮、天相、巨灵、国泰安、通联等。朝阳永续在分析师一致预期、盈利预测数据以及私募基金数据方面占据优势。天软科技在高频行情数据上比较突出。国泰安数据库主要为学术用途其中公司金融数据较为完善。
上面提到的这些厂商主要服务于金融机构。随着量化热潮的兴起,出现了向个人量化开发者和中小型投资机构出售量化数据的需求。这里面代表性的产品包括 pytdx,tushare,akshare,baostock,聚宽等等。
2023年下半年起,越来越多的人开始使用XtQuant库来获取行情数据。XtQuant是迅投QMT的一个Python SDK,它可以与以极简模式运行的QMT进行通讯,以获取行情数据、财务数据,并能以API方式执行交易。<br>
目前使用XtQuant获取普通行情数据是免费的,只要通过券商开通量化交易权限即可,开通这个权限,目前来看只有入金要求,没有费用。因此,QMT也可以算作是免费数据源。<br>
不过,不是所有的券商都开通了这一业务。
考虑到这门课的受众是刚入门的量化爱好者,因此我们选择数据源时,要综合考虑价格、质量和易用性等多个因素。我们将按照价格从低到高的顺序,为大家着重介绍一些个人投资者可以承担的产品。至于更高端的产品,您可以在精通量化策略开发,能产生稳定的收益之后,再自行接入使用。
在深入到具体的各个数据源之前,我们需要先了解一点基础的证券知识。
1. 交易所及证券代码
A 股有三个交易所,即上交所、深交所和北交所。上交所成立最早,其下有主板和科创板两个板块;深交所次之,它下面有主板、中小板和创业板三个板块;北交所则刚刚成立一年多,只有一个板块。
设立多个交易所和板块,是因为资本市场需要为不同成长风格的企业都能提供融资,这也是世界范围内证券交易所的常态,比如我们熟知的美国市场,纳斯达克交易所就以接纳全球高科技企业为主,我们科创板的定位就类似于纳斯达克。在同一个板块的所有股票,它们都有相同的起始编号,不同的板块,起始号码则各不相同。比如创业板是以 300 和 301 起头,科创板则以 688 起头,中小板以 002 起头,等等。
股票代码在每个交易所内的编号都是唯一的,但在不同的交易所之间,可能存在冲突的情况。所有的号码段都是为股票分配的,那么在编制指数时,应该安排什么号段呢?由于指数的编制机制与股票发行机制大不相同,所以,我们没法给它分配固定的号段,只能由交易所自己见机行事。因此,指数的编号就有可能与其它交易所中经营的股票品种相冲突。比如,深发展是 A 股发行较早 的一支股票(现名平安银行),它的编号是 000001,在深交所上市。而上交所在成立半年多后,开始编制综合指数,也使用了 000001 的编号,这就与深发展相冲突了。
因此,我们要了解的第一个概念,就是只有证券名称加上交易所代码(前缀或者后缀),才能唯一确定一支证券品种。比如,有的软件系统使用 XSHE 指代深交所,使用 XSHG 来指代上交所。如此一来,000001.XSHE 就唯一指向深发展,而 000001.XSHG 就唯一指向上综指。这是一种比较科学的方法。我们也可以把 000001.XSHG 称为上综指的规范名称,而把 000001 称为深发展或者上综指的简码。
我们平常在交流中,往往只使用简码。但当我们通过量化程序来获取数据时,则必须使用无歧义的代码。这个代码,相当于证券的身份证。
在这门课程中,我们主要使用 zillionare 来提供数据。不过,在介绍 zillionare 的数据方案之前,我们要先带大家学习第三方数据源的使用。因为 zillionare 本身也不能提供数据,它的数据也来自于第三方付费数据,定价也比较高,因此只在本课程中才能免费使用。
2. 除权和复权
股票存在配股、分拆、合并和发放股息等情形。当这些事件发生时,要么总股本数发生了变化(配股、分拆和合并的情形),要么每股包含的净权益发生了变化(发放股息)。这种情况下,每股包含的权益实际发生了变化,所以必须进行除权处理,这样才能保持财务上的一致性。
假设A股公司总股数1亿股。当前价格10元。则该公司的市值为10亿元。年终公司决定进行拆股,给出10送10的方案,这样总股数将变更为2亿股。如果此时不对股价进行调整,则该公司的市值将凭空增长1倍。这显然是不合理的。
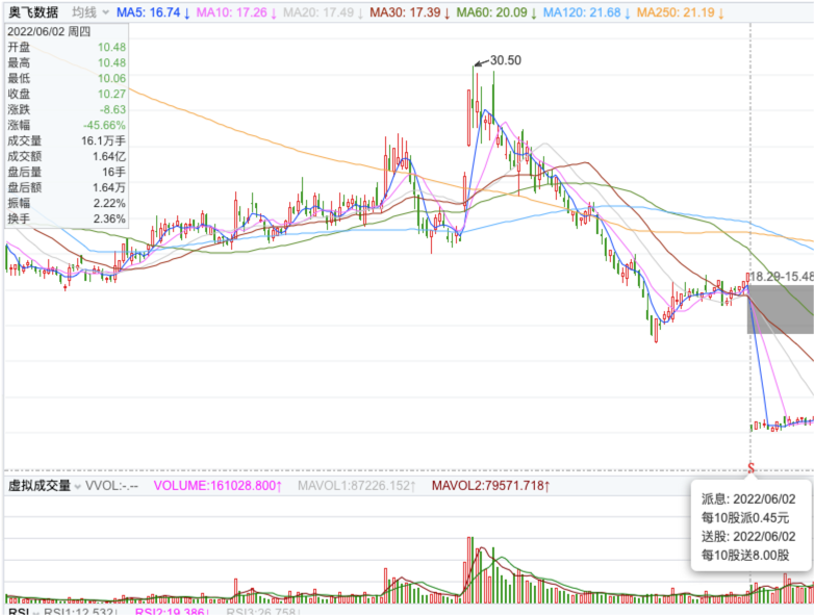
当除权发生时,股价就会出现较大的缺口。下图就显示了某支证券发生除权后,未进行复权处理的情况:
<div style="width:100%;text-align:center">
<img src="https://roim-picx-bpc.pages.dev/rest/kV9A67K.png" style="width:66%;margin: 10px auto;">
</div>
若使用未复权的价格来进行数据分析,将会出现技术指标发生实质性的改变(包括数据的统计特征),并且使用收益计算也会出现错误。
为了保证数据的连贯性,常通过前复权和后复权对价格序列进行调整。
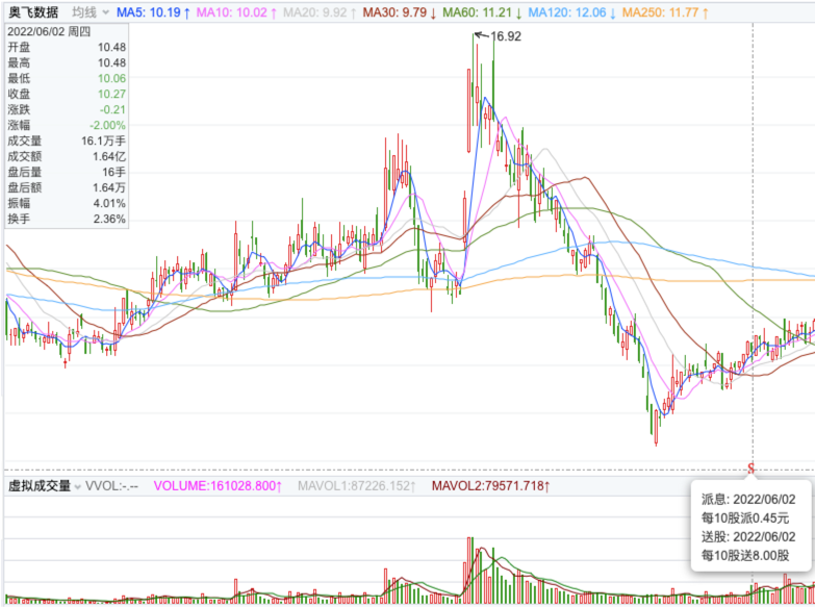
2.1. 前复权
<div style="width:100%;text-align:center">
<img src="https://roim-picx-bpc.pages.dev/rest/xkMA67K.png" style="width:66%;margin: 10px auto;">
</div>
保持当前价格不变,将历史价格向前进行增减,从而使股价连续,这种方法被称为前复权。前复权用来看盘非常方便,能一眼看出股价的历史走势,叠加各种技术指标也比较顺畅,是各种行情软件默认的复权方式。这种方法虽然很常见,但也有两个缺陷需要注意。
第一,为了保证当前价格不变,每次股票除权除息,均需要重新调整历史价格,因此其历史价格是随时可变的。这会导致在不同时点看到的历史前复权价可能出现差异。如果我们使用的回测框架不能正确处理这种情况,将会引入未来数据。
第二,对于有持续分红的公司来说,长时间的前复权价,可能导致早期价格出现负值。即使一些数据源采用复权因子的做法,避免了负值的出现,但一旦早期价格低于(或者接近)1分钱这个事实上的最小单位,对价格的研究就不再有任何意义。
如果某股的股价经过前复权,在早期它的价格变为0.008, 0.009, 0.001这样低于1分钱的数据,就会导致很多错误:因为股价的最小单位是0.01。即使部分软件能避免这个问题,继续复权时,股价变成7位小数之后,计算机由于单精度浮点数精度问题,将无法区分这些数字。
 发表于 2024-9-3 23:40:53
|
查看: 3174|
回复: 5
发表于 2024-9-3 23:40:53
|
查看: 3174|
回复: 5 |Archiver|手机版|小黑屋|bioinfoer
( 萌ICP备20244422号 )
|Archiver|手机版|小黑屋|bioinfoer
( 萌ICP备20244422号 )

{kind=link}
{kind=link}
{kind=link}