notebook高级技巧
# notebook高级技巧网上有很多jupyter的使用技巧。但我相信,这篇文章会让你全面涨姿势。很多用法,你应该没见过。
## 1. 环境变量
默认情况下,jupyter notebook/lab不会读取你主机的环境变量。如果有一些secret(比如账号、密码)需要通过环境变量传递给notebook的话,我们需要修改它的kernel.json文件。
首先,我们通过 `jupyter kernelspec list`来获取kernel所在的位置。比如,在我们的课程环境中,我们将得到以下输出:
```bash
>>> jupyter kernelspec list
Available kernels:
python3 C:\Users\Administrator\software\anaconda3\envs\lianghua\share\jupyter\kernels\python3
lianghua C:\Users\Administrator\AppData\Roaming\jupyter\kernels\lianghua
```
我们的课程环境中要使用的kernel,就是lianghua这个名字对应的kernel。下面,我们修改它的配置文件:
```
用windows vscode修改
C:\Users\Administrator\AppData\Roaming\jupyter\kernels\lianghua\kernel.json
```
这个文件类似于:
```json
{
"argv": [
"C:\\Users\\Administrator\\software\\anaconda3\\envs\\lianghua\\python.exe",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "lianghua3.12.4",
"language": "python",
"metadata": {
"debugger": true
}
}
```
我们增加一项,名为"env":
```json
{
"metadata": ...,
"env": {
"TZ": "Asia/Shanghai"
}
}
```
保存后,在notebook菜单栏中选择shutdown kernel,然后重新打开notebook文件。这样我们就可以在notebook中看到新增的环境变量TZ了:
```bash
%env #可以看到'AZ'项为上海
```
在课程学习中,需要配置你自己的tushare-token,或者jqdatasdk的账号、密码,建议你通过这种方式来配置。
## 2. 魔法命令
几乎每一个使用过Jupyter Notebook的人,都会注意到它的魔法(magic)功能。具体来说,它是一些适用于整个单元格、或者某一行的魔术指令。
比如,我们常常会好奇,究竟是pandas的刀快,还是numpy的剑更利。在量化中,我们常常需要寻找一组数据的某个分位数。在numpy中,有percentile方法,quantile则是她的pandas堂姊妹。要不,我们就让这俩姐妹比一比身手好了。有一个叫timeit的魔法,就能完成这任务。
不过,我们先得确定她们是否真有可比性。
```python
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
print(np.percentile(array, 95))
series.quantile(0.95)
```
```
1.6430590195631314
1.6430590195631314
```
两次输出的结果都是一样,说明这两个函数确实是有可比性的。
在上面的示例中,要显示两个对象的值,我们只对前一个使用了print函数,后一个则省略掉了。这是notebook的一个功能,它会默认地显示单元格最后输出的对象值。这个功能很不错,要是把这个语法扩展到所有的行就更好了。
不用对神灯许愿,这个功能已经有了!只要进行下面的设置:
```python
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
```
在一个单独的单元格里,运行上面的代码,之后,我们就可以省掉print:
```python
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
# 这一行会输出一个浮点数
np.percentile(array, 95)
# 这一行也会输出一个浮点数
series.quantile(0.95)
```
```
1.6467672500218886
1.6467672500218886
```
这将显示出两行一样的数值。这是今天的第一个魔法。
现在,我们就来看看,在百万数据中探囊取物,谁的身手更快一点?
```python
import numpy as np
import pandas as pd
array = np.random.normal(size=1_000_000)
series = pd.Series(array)
%timeit np.percentile(array, 95)
%timeit series.quantile(0.95)
```
```
4.59 ms ± 10.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.82 ms ± 14.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
我们使用%timeit来测量函数的运行时间。其输出结果是:
```
之前测试过是反过来的结果
26.7 ms ± 5.67 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
21.6 ms ± 837 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
之前的结论看起来pandas更快啊。而且它的性能表现上更稳定,标准差只有numpy的1/7。mean±std什么的,量化人最熟悉是什么意思了。
新台式电脑又是numpy更快,可能后续再测试对比吧。
这里的timeit,就是jupyter支持的魔法函数之一。又比如,在上面打印出来的分位数,有16位小数之多,真是看不过来啊。能不能只显示3位呢?当然有很多种方法做到这一点,比如,我们可以用f-str语法:
```python
f"{np.percentile(array, 95):.3f}"
```
```
'1.648'
```
啰哩啰嗦的,说好要Pythonic的呢?不如试试这个魔法吧:
```python
%precision 3
np.percentile(array, 95)
```
```
'%.3f'
1.648
```
之后每一次输出浮点数,都只有3位小数了,是不是很赞?
如果我们在使用一个第三方的库,看了文档,(下面的omicron我还没安装好,所以沿用了网上的代码)觉得它还没说明白,想看它的源码,怎么办?可以用psource魔法:
```python
from omicron import tf
%psource tf.int2time
```
这会显示tf.int2time函数的源代码:
```markdown
@classmethod
def int2time(cls, tm: int) -> datetime.datetime:
"""将整数表示的时间转换为`datetime`类型表示
examples:
>>> TimeFrame.int2time(202005011500)
datetime.datetime(2020, 5, 1, 15, 0)
Args:
tm: time in YYYYMMDDHHmm format
Returns:
转换后的时间
"""
s = str(tm)
# its 8 times faster than arrow.get()
return datetime.datetime(
int(s[:4]), int(s), int(s), int(s), int(s)
)
```
看起来Zillionare-omicron的代码,文档还是写得很不错的。能和numpy一样,在代码中包括示例,并且示例能通过doctest的量化库,应该不多。
Jupyter的魔法很多,记不住怎么办?这里有两个魔法可以用。一是%lsmagic:
```python
%lsmagic
```
这会显示为:
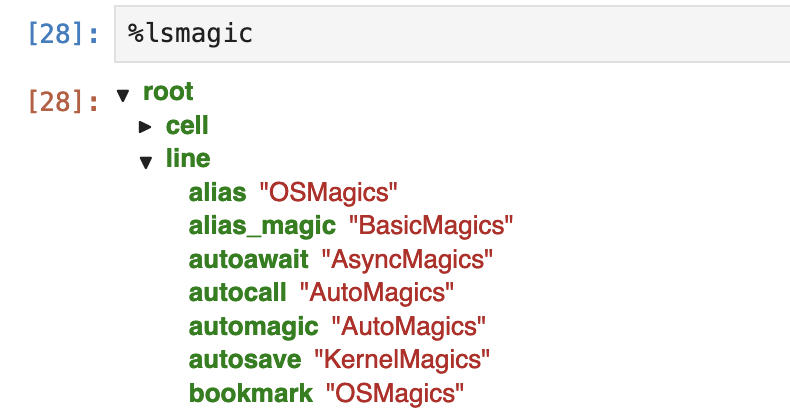
确实太多魔法了!不过,很多命令是操作系统命令的一部分。另一个同样性质的魔法指令是%quickref,它的输出大致如下:
```text
IPython -- An enhanced Interactive Python - Quick Reference Card
================================================================
obj?, obj?? : Get help, or more help for object (also works as
?obj, ??obj).
?foo.*abc* : List names in 'foo' containing 'abc' in them.
%magic : Information about IPython's 'magic' % functions.
Magic functions are prefixed by % or %%, and typically take their arguments
without parentheses, quotes or even commas for convenience.Line magics take a
single % and cell magics are prefixed with two %%.
Example magic function calls:
...
```
输出内容大约有几百行,一点也不quick!
## 3. 在vscode中使用jupyter
如果有可能,我们应该尽可能地利用vscode的jupyter notebook。vscode中的jupyter可能在界面元素的安排上弱于浏览器(即原生Jupyter),比如,单元格之间的间距太大,无法有效利用屏幕空间,菜单命令少于原生jupyter等等。但仍然vscode中的jupyter仍然有一些我们难于拒绝的功能。
首先是代码提示。浏览器中的jupyter是BS架构,它的代码提示响应速度比较慢,因此,只有在你按tab键之后,jupyter才会给出提示。在vscode中,代码提示的功能在使用体验上与原生的python开发是完全一样的。
其次,vscode中的jupyter的代码调试功能更好。原生的Jupyter中进行调试可以用%pdb或者%debug这样的magic,但体验上无法与IDE媲美。
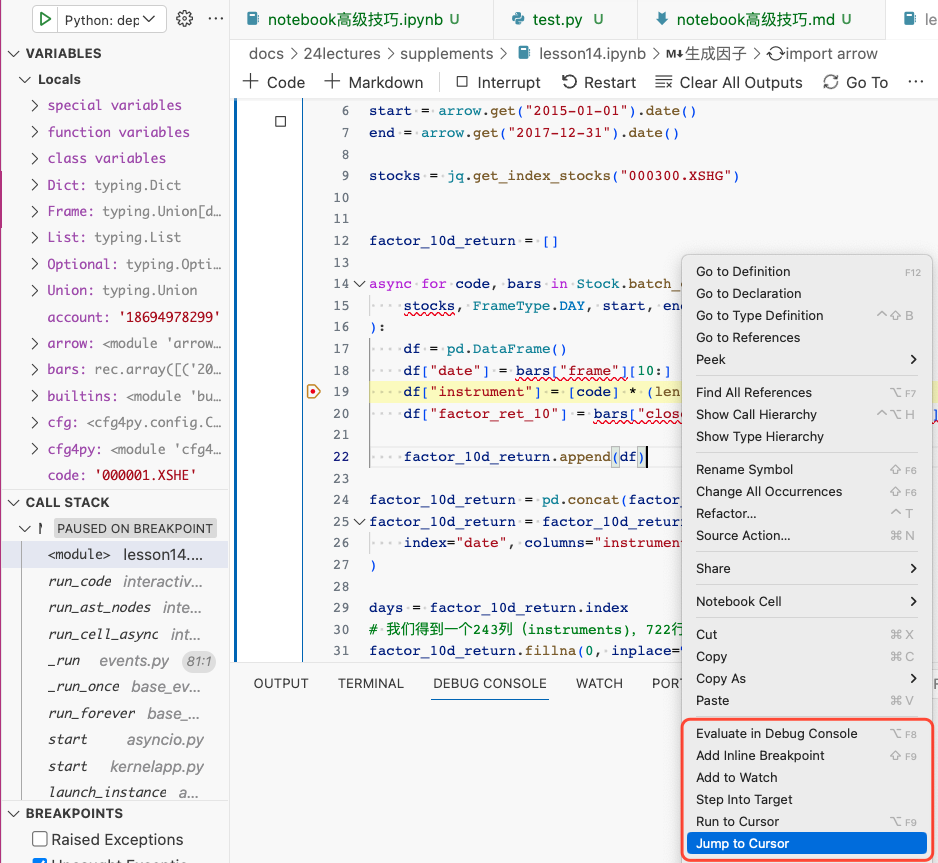
还有一点功能是原生Jupyter无法做到的,就是最后编辑位置导航。如果我们有一个很长的notebook,在第100行调用第10行写的一个函数,发现出错,要转到第10行进行修改,修改完成后,再回到第100行继续编辑,这在原生jupyter中是做不到的。通常我们只能在这些地方,插入markdown cell,然后利用标题来进行快速导航,但仍然无法准确定位到具体的行。但这个功能在IDE里是必备功能。我们在vscode中编辑notebook,这个功能仍然具备。
notebook适于探索。但如果最终我们要将其工程化,我们还必须将其转换成为python文件。vscode提供了非常好的notebook转python文件功能。下面是本文的notebook版本转换成python时的样子:

转换后的notebook中,原先的markdown cell,转换成注释,并且以# %% 起头;而原生的python cell,则是以# %%起头,这些单元格仍然是可以执行的。由于配置的原因,在我的工作区里,隐藏了这些toolbar,实际上它们看起来像这样:
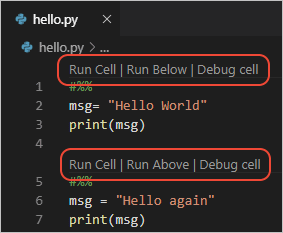
这个特性被称为Python Interactive Window,可以在vscode的文档vscode中查看。
我们从notebook转换成python文件,但它仍然可以像notebook一样,逐单元格执行,这就像是个俄罗斯套娃。
## 4. JupySQL - 替换你的数据库查询工具
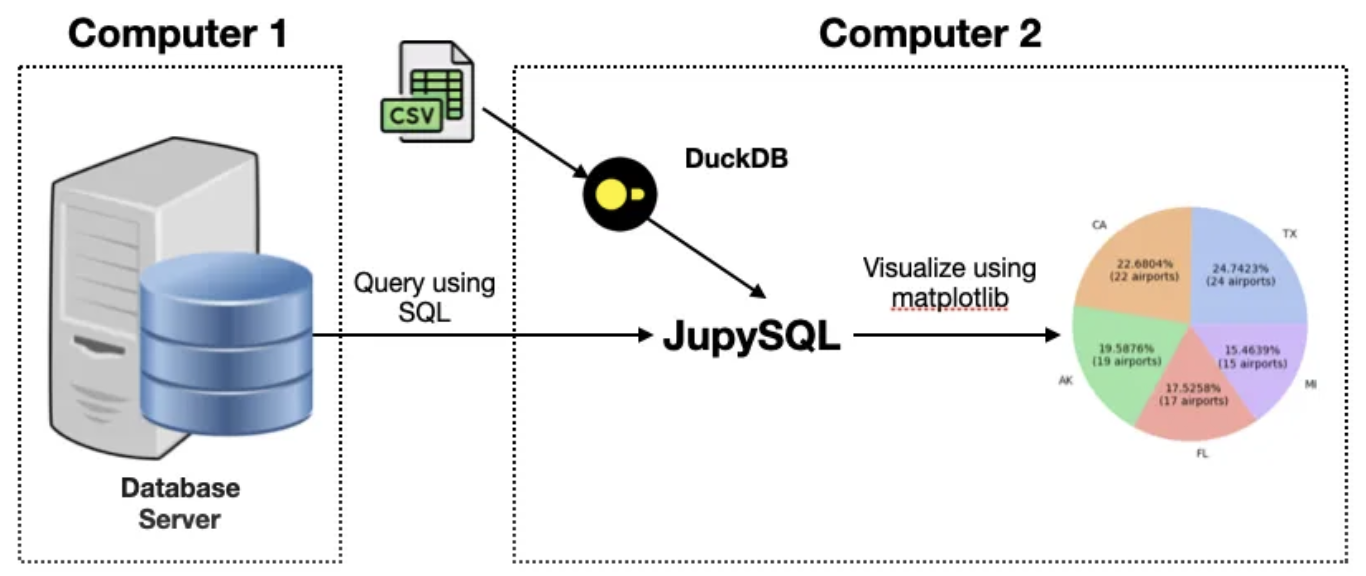
JupySQL是一个运行在Jupyter中的sql查询工具。它支持对传统关系型数据库(PostgreSQL, MySQL)、列数据库(ClickHouse),数据仓库(Snowflake, BigQuery, Redshift, etc)和嵌入式数据库(SQLite, DuckDB)的查询。
之前我们不得不为每一种数据库寻找合适的查询工具,找到开源、免费又好用的其实并不容易。有一些工具,设置还比较复杂,比如像Tabix,这是ClickHouse有一款开源查询工具,基于web界面的。尽管它看起来简单到甚至无须安装,但实际上这种新的概念,导致一开始会引起一定的认知困难。在有了JupySQL之后,我们就可以仅仅利用我们已知的概念,比如数据库连接串,SQL语句来操作这一切。
除了查询支持之外,JupySQL的另一特色,就是自带部分可视化功能。这对我们快速探索数据特性提供了方便。
### 4.1. 安装JupySQL
现在,打开一个notebook,执行以下命令,安装JupySQL:
```shell
%pip install jupysql duckdb-engine --quiet
```
之前你可能是这样使用pip:
```shell
! pip install jupysql
```
在前一章我们学习了Jupyter魔法之后,现在你知道了,%pip是一个line magic。
显然,JupySQL要连接某种数据库,就必须有该数据库的驱动。接下来的例子要使用DuckDB,所以,我们安装了duckdb-engine。
```{admonition}
DuckDB是一个性能极其强悍、有着现代SQL语法特色的嵌入式数据库。从测试上看,它可以轻松管理500GB以内的数据,并提供与任何商业数据库同样的性能。
```
在安装完成后,需要重启该kernel。JupySQL是作为一个扩展出现的。要使用它,我们要先用Jupyter魔法把它加载进来,然后通过%sql魔法来执行sql语句:
```bash
%load_ext sql
# 连接duckdb。下面的连接串表明我们将使用内存数据库
%sql duckdb://
# 这一行的输出结果为 1,表明JupySQL正常工作了
%sql select 1
```
### 4.2. 数据查询(DDL和DML)
不过,我们来点有料的。我们从baostock.com上下载一个A股历史估值的示例文件。这个文件是Excel格式,我们使用pandas来将其读入为DataFrame,然后进行查询:
```python
import pandas as pd
df = pd.read_excel("./history_A_stock_valuation_indicator_data.xlsx")
%load_ext sql
# 创建一个内存数据库实例
%sql duckdb://
# 我们将这个dataframe存入到DuckDB中
%sql --persist df
# 列出数据库中有哪些表
%sqlcmd tables
# 列出表'df'有哪些列
%sqlcmd columns -t df
```
最后一行命令将输出以下结果:
| name | type | nullable | default | autoincrement | comment |
| --------- | ---------------- | -------- | ------- | ------------- | ------- |
| index | BIGINT | True | None | False | None |
| date | VARCHAR | True | None | False | None |
| code | VARCHAR | True | None | False | None |
| close | DOUBLE PRECISION | True | None | False | None |
| peTTM | DOUBLE PRECISION | True | None | False | None |
| pbMRQ | DOUBLE PRECISION | True | None | False | None |
| psTTM | DOUBLE PRECISION | True | None | False | None |
| pcfNcfTTM | DOUBLE PRECISION | True | None | False | None |
作为数据分析师,或者量化研究员,这些命令基本上满足了我们常用的DDL功能需求。在使用pgAdmin的过程中,要找到一个表格,需要沿着servers > server > databases > database > Schema > public > Tables这条路径,一路展开所有的结点才能列出我们想要查询的表格,不免有些烦琐。JupySQL的命令简单多了。
现在,我们预览一下这张表格:
```python
%sql select * from df limit 5
```
我们将得到如下类似的输出:
| index | date | code | close | peTTM | pbMRQ | psTTM | pcfNcfTTM |
| ----- | ---------- | --------- | ----- | -------- | -------- | -------- | --------- |
| 0 | 2022-09-01 | sh.600000 | 7.23| 3.978631 | 0.370617 | 1.103792 | 1.103792|
| 1 | 2022-09-02 | sh.600000 | 7.21| 3.967625 | 0.369592 | 1.100739 | 1.100739|
| 2 | 2022-09-05 | sh.600000 | 7.26| 3.99514| 0.372155 | 1.108372 | 1.108372|
| 3 | 2022-09-06 | sh.600000 | 7.26| 3.99514| 0.372155 | 1.108372 | 1.108372|
| 4 | 2022-09-07 | sh.600000 | 7.22| 3.973128 | 0.370105 | 1.102266 | 1.102266|
%sql是一种line magic。我们还可以使用cell magic,来构建更复杂的语句:
```sql
%%sql --save agg_pe
-- example 1
select code, min(peTTM), max(peTTM), mean(peTTM)
from df
group by code
```
<span style="None">Running query in 'duckdb://'</span>
<table>
<thead>
<tr>
<th>code</th>
<th>min(peTTM)</th>
<th>max(peTTM)</th>
<th>mean(peTTM)</th>
</tr>
</thead>
<tbody>
<tr>
<td>sh.600000</td>
<td>3.967961</td>
<td>6.929481</td>
<td>5.2185864404432145</td>
</tr>
</tbody>
</table>
```{tip}
在JupySQL安装后,还会在工具栏出现一个Format SQL的按钮。如果一个单元格包含sql语句,点击它之后,它将对sql语句进行格式化,并且语法高亮显示。
```
使用cell magic语法,整个单元格都会当成sql语句,这也使得我们构建复杂的查询语句时,可以更好地格式化它。这里在%%sql之后,我们还使用了选项 --save agg_pe,目的是为了把这个较为复杂、但可能比较常用的查询语句保存起来,后面我们就可以再次使用它。
我们通过%sqlcmd snippets来查询保存过的查询语句:
```python
%sqlcmd snippets
```
<table>
<thead>
<tr>
<th>Stored snippets</th>
</tr>
</thead>
<tbody>
<tr>
<td>agg_pe</td>
</tr>
</tbody>
</table>
这将列出我们保存过的所有查询语句,刚刚保存的agg_pe也在其中。接下来,我们就可以通过%sqlcmd来使用这个片段:
```python
query = %sqlcmd snippets agg_pe
# 这将打印出我们刚刚保存的查询片段
print(query)
# 这将执行我们保存的代码片段
%sql {{query}}
```
```
select code, min(peTTM), max(peTTM), mean(peTTM)
from df
group by code
```
<span style="None">Running query in 'duckdb://'</span>
<table>
<thead>
<tr>
<th>code</th>
<th>min(peTTM)</th>
<th>max(peTTM)</th>
<th>mean(peTTM)</th>
</tr>
</thead>
<tbody>
<tr>
<td>sh.600000</td>
<td>3.967961</td>
<td>6.929481</td>
<td>5.2185864404432145</td>
</tr>
</tbody>
</table>
最终将输出与example-1一样的结果。
### 4.3. JupySQL的可视化
JupySQL还提供了一些简单的绘图,以帮助我们探索数据的分布特性。
```python
%sqlplot histogram -t df -c peTTM pbMRQ # 执行报错AttributeError: 'NoneType' object has no attribute 'gca',暂未解决
```
JupySQL提供了box, bar, pie和histogram。可以使用自己的数据进行探索。
## 5. 更强大的可视化工具
不过,JupyerSQL提供的可视化功能并不够强大。有一些专业工具,它们以pandas DataFrame为数据载体,集成了数据修改、筛选、分析和可视化功能。这一类工具有, Qgrid(来自 Quantpian),PandasGUI,dtale 和 mitosheet。
Qgrid的目标是为量化研究提供数据探索的工具。他们在Youtube上提供了一个presentation,介绍了如何使用Qgrid来探索数据的边界。不过,随着QuantPian关张大吉,所有这些工具都不再有人维护,因此我们也不重点介绍了。
PandasGUI在notebook中启动,但它的界面是通过Qt来绘制的,因此,启动以后,它会有自己的专属界面,而且是以独立的app来运行。它似乎要求电脑是Windows。
Mitosheet的界面非常美观,可以通过 `pip install mitosheet`,从notebook中进行安装。不过,安装完成后,需要重启jupyterlab/notebook server。仅仅重启kernel是不行的,因为为涉及到界面的修改。
重启后,在Notebook的工具条栏,会多出一个“New Mitosheet”的按钮,点击它,就会新增一个单元格,其内容为:
```python
import mitosheet
mitosheet.sheet(analysis_to_replay="id-sjmynxdlon")
```
并且自动运行这个单元格,调出mito的界面。注册登陆后,下面是mitto中可视化一例:
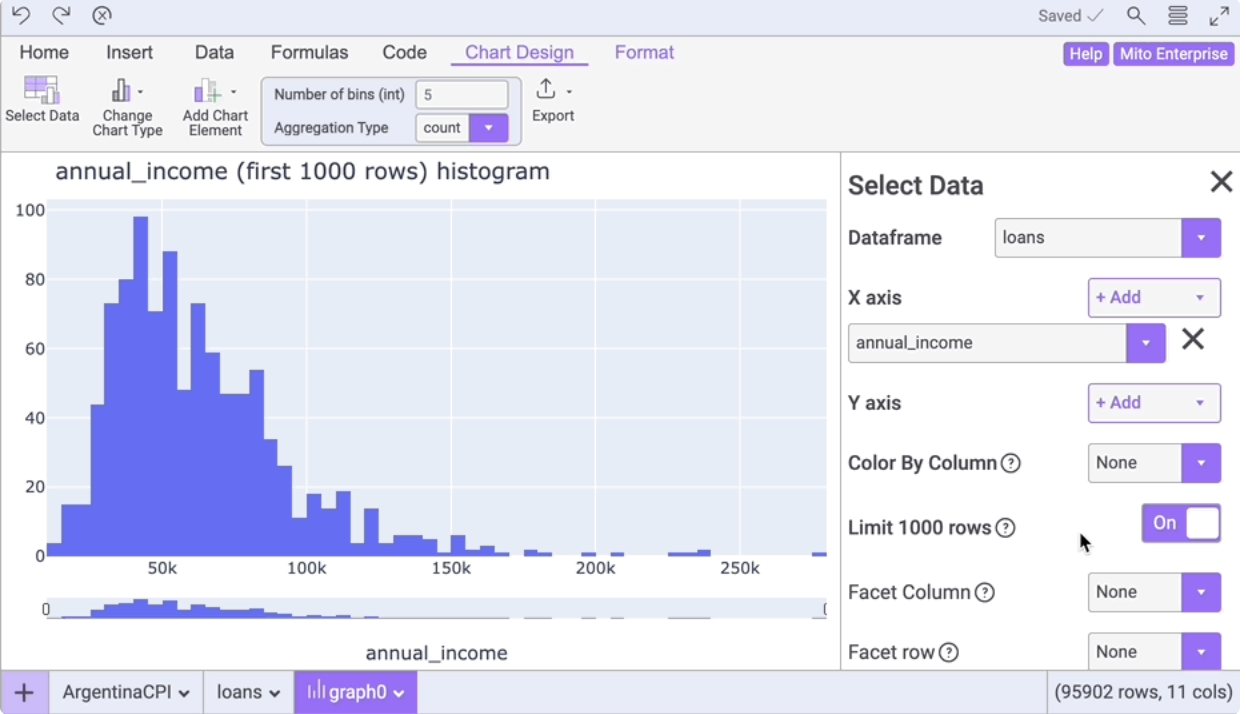
mitto有免费版和专业版的区分,而且似乎它会把数据上传到服务器上进行分析,所以在国内使用起来,感觉不是特别流畅。
与上面介绍的工具相比,dtale似乎没有这些工具有的这些短板。
我们在notebook中通过 `pip install dtale`来安装dtale。安装后,重启kernel。然后执行:
```python
import dtale
dtale.show(df)
```
这会显加载以下界面:
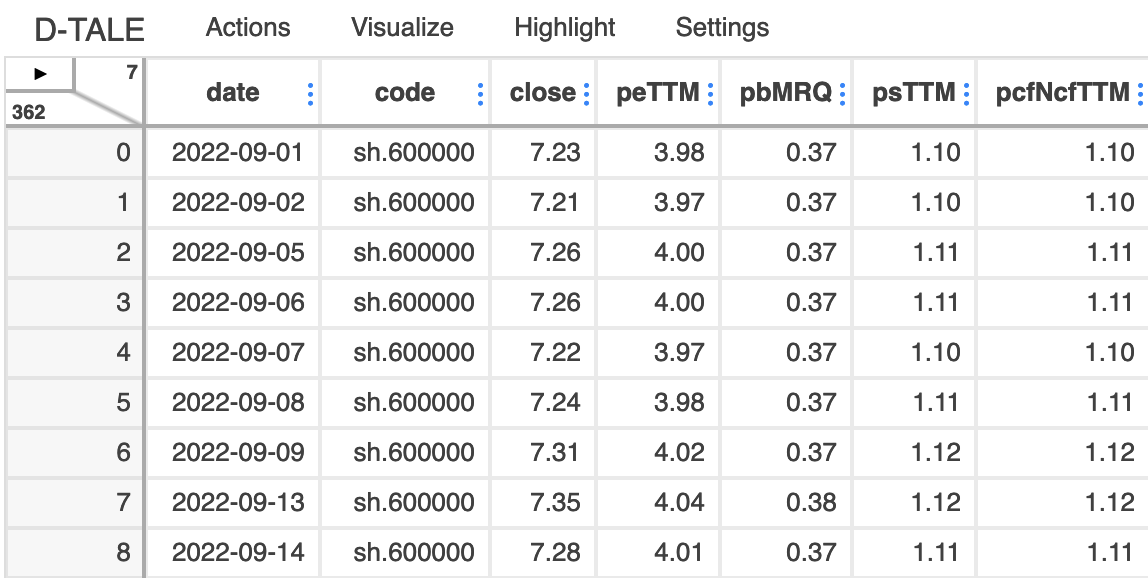
在左上角有一个小三角箭头,点击它会显示菜单:
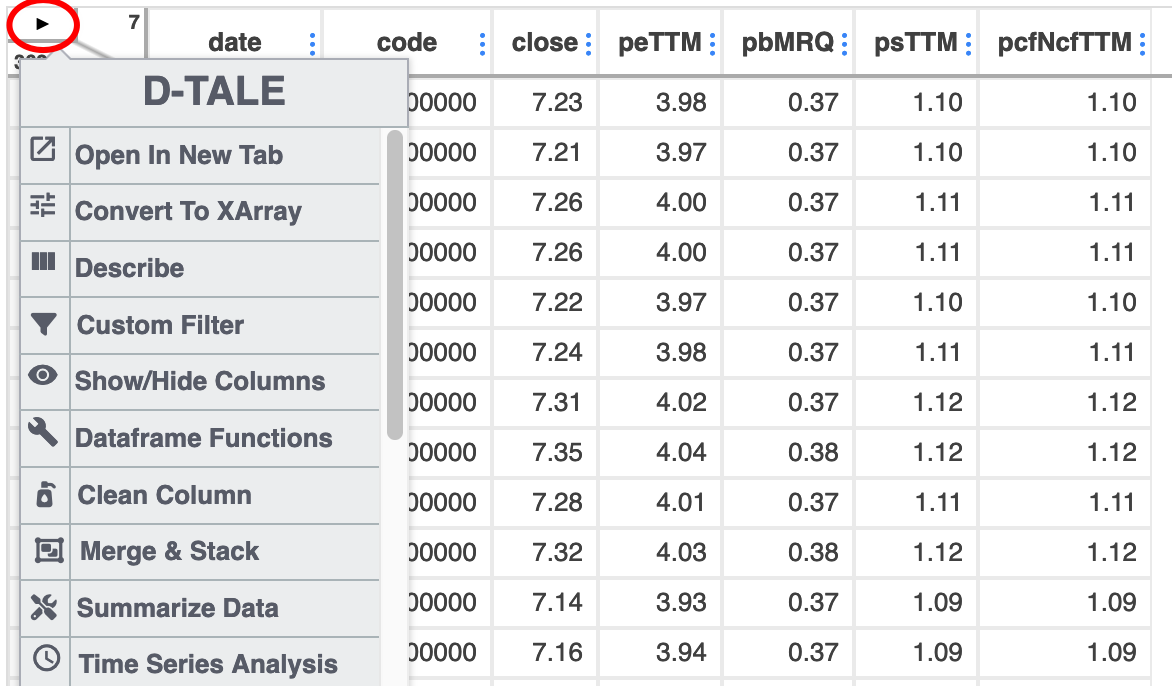
我们可以点击describe菜单项看看,它的功能要比 `df.describe()`强大不少。df.describe只能给出均值、4分位数值,方差,最大最小值,dtale还能给出diff, outlier, kurtosis, skew,绘制直方图,Q-Q图(检查是否正态分布)。
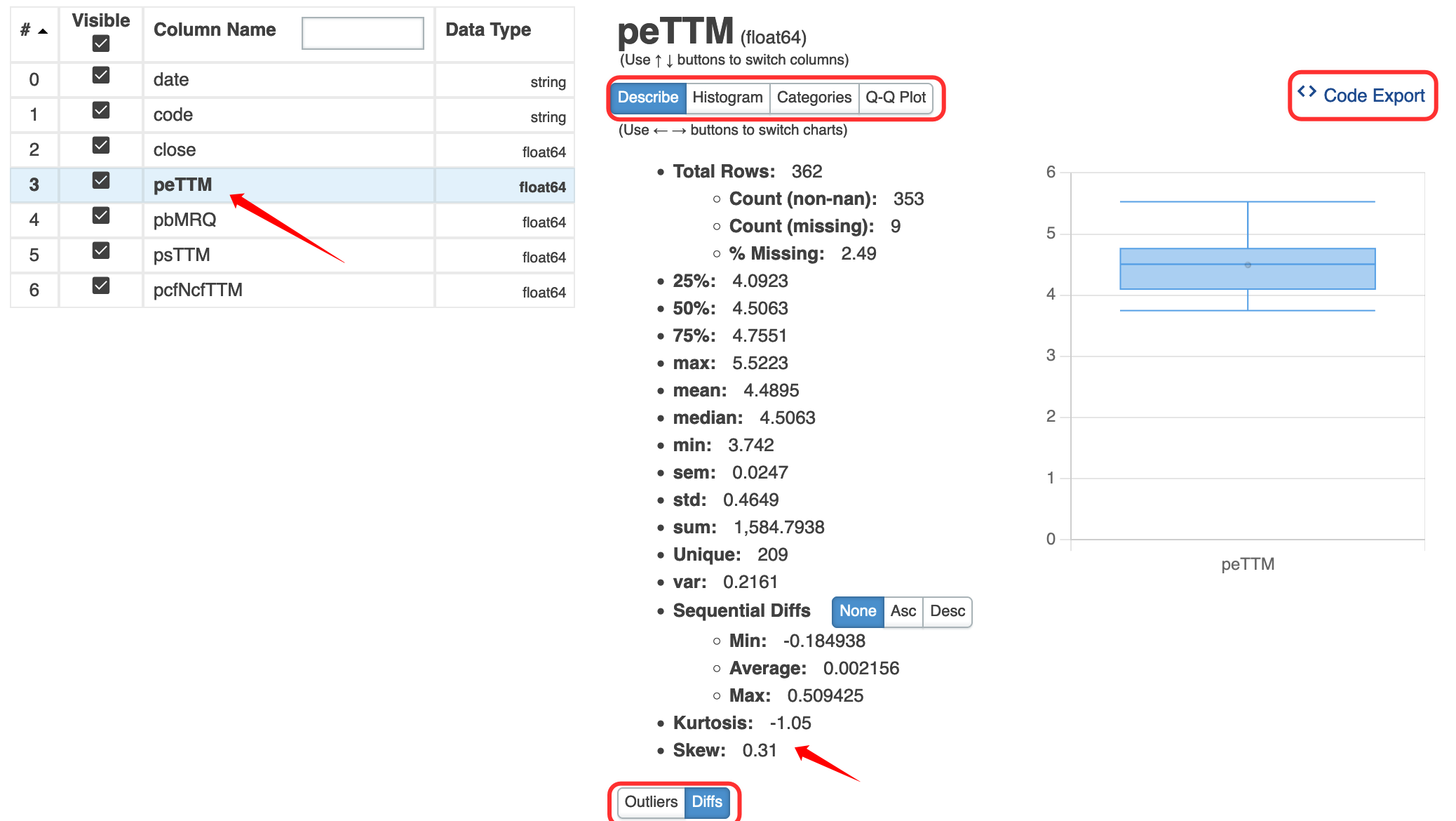
注意我们可以导出进行这些计算所用的代码!这对数据分析的初学者确实很友好。
这是从中导出的绘制qq图的代码:
```python
# DISCLAIMER: 'df' refers to the data you passed in when calling 'dtale.show'
import numpy as np
import pandas as pd
import plotly.graph_objs as go
if isinstance(df, (pd.DatetimeIndex, pd.MultiIndex)):
df = df.to_frame(index=False)
# remove any pre-existing indices for ease of use in the D-Tale code, but this is not required
df = df.reset_index().drop('index', axis=1, errors='ignore')
df.columns = # update columns to strings in case they are numbers
s = df[~pd.isnull(df['peTTM'])]['peTTM']
import scipy.stats as sts
import plotly.express as px
qq_x, qq_y = sts.probplot(s, dist="norm", fit=False)
chart = px.scatter(x=qq_x, y=qq_y, trendline='ols', trendline_color_override='red')
figure = go.Figure(data=chart, layout=go.Layout({
'legend': {'orientation': 'h'}, 'title': {'text': 'peTTM QQ Plot'}
}))
figure
# If you're having trouble viewing your chart in your notebook try passing your 'chart' into this snippet:
#
# from plotly.offline import iplot, init_notebook_mode
#
# init_notebook_mode(connected=True)
# chart.pop('id', None) # for some reason iplot does not like 'id'
# iplot(chart)
```
有了这个功能,如果不知道如何通过plotly来绘制某一种图,那么就可以把数据加载到dtale,用dtale绘制出来,再导出代码。作为量化人,可能最难绘制的图就是K线图了。这个功能,dtale有。
最后,实际上dtale是自带服务器的。我们并不一定要在notebook中使用它。安装dtale之后,可以在命令行下运行 `dtale`命令,然后再打开浏览器窗口就可以了。更详细的介绍,可以看这份中文文档。
页:
[1]